Brooke Boser
Brooke is the Director of the Marketing Intelligence Team with a passion for helping to make data make sense. When not buried in Google Analytics, she enjoys learning, laughing, and talking all things sports.
MADS Conference: 3 Big Topics for Marketing Professionals
In April of this year myself and our President, Susan Murphy attended the Marketing Analytics and Data Science (MADS) conference in San Francisco. Through keynote speakers and breakout sessions, the purpose of this conference was to bring together those responsible for collecting, cleaning, and analyzing data within organizations and agencies in order to expand our knowledge on how to effectively pull out trends and insights from our marketing activities, as well as solve larger business problems.

It was interesting to see people from all over North America and beyond come together for this conference and to understand that almost everyone has the same problems with data: the data set is too big, it’s not complete (systems aren’t talking to each other), it’s not clean (ie. campaigns aren’t named consistently). Or, not all channels are given proper attribution, we are reactive instead of predictive, all of our data is in spreadsheets, etc. No matter where you go, no matter what industry, the challenges with data are similar.
For the purpose of this blog post I have focused on three main areas of discussion that I felt are the most global: Data Management, Moving from Reactive to Predictive Analytics, and Attribution. The aim is by the end of this post to have a better understanding of where the pain points within these topics are and what we can do moving forward, so let’s get to it!
Data Management – Starting with a Data Lake or Data Warehouse
“Without a systematic way to start and keep data clean, bad data will happen.” – Donato Diorio
The goal of any marketing intelligence team is to understand the end to end flow of data available to them. What data do we have? Where is it stored? How do we pull it together? What insights can we gain? It’s developing an end-to-end value chain in terms of data that looks like this:
Collection > Storage > Visualization > Analysis > Prediction
Data Lakes or Data Warehouses fit in at the Collection and Storage stage, which really sets the tone for success in the stages that follow. In order to understand this deeper let’s look at a couple definitions:
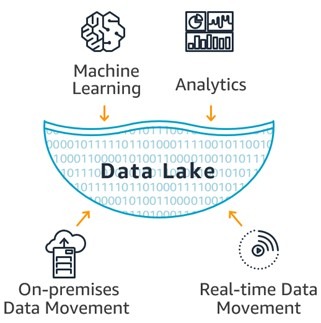
Data Lake – AWS defines a data lake as “a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.”
Data Warehouse – A data warehouse is constructed by integrating data from multiple and diverse sources that support analytical reporting, structured and/or ad hoc queries, and decision making.
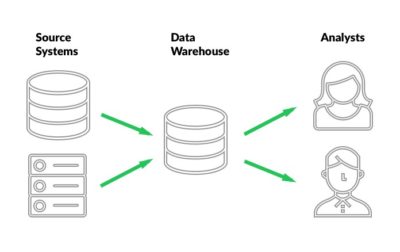
In other words, a data warehouse is a repository for structured, filtered data that has already been processed for a specific purpose, whereas a data lake is a place to store all of your raw data. It is the core of the business intelligence system which is built for data analysis and reporting. Without it we are looking at data in silos and making business decisions through only one lens. By bringing all of the data together in one place we can start to make holistic business insights, which in the end leads to greater impact for the business as a whole and not just the marketing group. We can also move from reactive analysis to predictive analysis, which is what we will discuss next.
Move from Reactive to Predictive – Humans + Machines = Future of Work
“Data beats emotions.” – Sean Rad
Moving from reactive analytics to predictive analytics is a lot of work. Data usually has to go through a series of steps (collection, storage, cleaning, etc) before it can even be analyzed, and by that time the insights you are gaining from the data could be outdated. This continually puts analysts and the business in the position of looking at what happened in the past rather than predicting what might occur in the future.
Machine Learning, while a big topic with many discussion points, does serve a very functional purpose today in being able to take data and make predictions. Before we dive into that, however, let’s look at a few key terms having to do with this area:
- Big Data – having data all in one place
- Analytics – counting things
- Data Science – counting things cleverly
- Predictive Analysis – using models to predict business outcomes, usually done by the Data Scientists using statistical programming languages such as R and Python
- Machine Learning – data science with prediction and feedback loops, repeatable processes done by machines (computers)
- Artificial Intelligence – deep learning, neural learning
Different predictive models that are used within the marketing industry include Lead Generation, Targeted Profiling of Customers, Customer Segmentation, Customer Lifetime Value, Reduced Customer Churn, and more. As with any data analysis, the output will only be as good as the input, but when executed right using predictive models can help improve marketing campaigns (although this type of modelling can be extended to any business unit).
Machine Learning systems are made to build upon already acquired knowledge. This knowledge starts with the data scientist and their ability to “feed the machine”. Just as humans learn from experience, Machine Learning systems learn from data. This is why it is so important for a Marketing Intelligence team to have vast knowledge in data analysis, statistics, and programming languages such as R and Python. When you can pull all of that knowledge together, powerful insights can happen.
At the conference, Avinash Kaushik gave us two goals to strive for in 2019 – have 10% of your people trained in Machine Learning and have 25% of your business functions powered by Machine Learning. For most of us this is a lofty goal, but it’s definitely a starting place in order to move into the future of marketing analysis.
Attribution
“Errors using inadequate data are much less than those using no data at all.” – Charles Babbage
Marketing attribution provides a level of understanding of what combination of events in what particular order influence individuals to engage in a desired behaviour, typically referred to as a conversion.
Channels that we would want to assign an attributed value to include Broadcast TV, Broadcast Radio, Out of Home, Cinema, Paid Search, Display, Paid Social, Organic Social, etc. Any interaction point along the way of a customer journey should be given some value. As per Salesforce, the average customer uses 10 channels to communicate with companies, which has made marketing attribution one of the most hotly debated topics of our industry.
There are many different approaches to marketing attribution, which does not help the confusion. Here’s just two of these:
- Single Source Attribution gives all credit to one touchpoint (think First Touch or Last Touch)
- Multi-Touch Attribution attempts to give all channels that contributed to the final conversion a piece of the credit (think Time Decay or Linear).
In the end, a Custom Attribution model gives organizations / agencies the most flexibility as they can choose their own weighting based on the industry, channels used, and buyer behaviour. However, a custom model takes the biggest investment in terms of time and money spent in order to develop. This article from Bizible has a great breakdown of 11 Attribution Models explained.
All of that said, the biggest challenge with Attribution isn’t necessarily choosing which model works best for you, but it’s making sure you have all of the data from all of the channels that are being used within your marketing mix. For example, just using Google Analytics to define your attribution model is great for all of your digital channels, but it doesn’t take into consideration offline channels like Out of Home or Broadcast Radio marketing, for instance, unless a user visits the website after seeing one of those ads (and you have a tracking mechanism in place to identify those visits, such as vanity URLs). When running marketing campaigns, it’s important to know how you can track both online and offline channels in order to attribute value accurately. We found this great breakdown of different online and offline techniques used for attribution put together by Clearcode.
In the end, it’s hard to find the perfect model. First, you need to start where you can, then you need to identify which model you want to test next and go from there. Depending on the time and resources available to you this could be a quick process, or it could take a year or more. The main thing is that you are thinking about it and making strides to get to the next level on the evolutionary journey of attribution:
Last-click > First & Last Click > Fractional > Rules-based > Statistical Models
In conclusion, you can see that the major pain points within the marketing industry are not easily solutionable. There are many steps, many variables, and many opinions to sort through when trying to apply the best solution to your organization or agency. The main takeaway for me is that we are all on this journey together. We may be at different stages depending on the maturity of our organizations, but at one point or another, we have all dealt with the same problems. Data is a beast, and in the end, I come back to Mark Twain and his interpretation of data, which is: “Data is like garbage. You’d better know what you’re going to do with it before you start collecting it.”